Recovery Post-Crash
Concept. Post-crash recovery runs three passes over the WAL (Analysis (figure out which transactions were in flight at the crash), REDO (replay every committed change to bring the on-disk data back up to the log), and UNDO (reverse the changes of any transaction that didn't COMMIT))leaving the database fully consistent and ready for new traffic.
Intuition. When the server crashes mid-rush, the log shows Mickey, Minnie, and Daffy were all mid-Premium-purchase. Analysis scans the log and labels them: Mickey COMMITted, Minnie COMMITted, Daffy did not. REDO replays Mickey's and Minnie's writes in case their account-table pages never flushed. UNDO reverses Daffy's charge. His transaction never finished. After three passes, Mickey and Minnie are Premium, Daffy is refunded, and the database is back online.
The Crash Scenario
A database crash leaves us with a few cold facts:
-
Committed transactions might not be fully on disk.
-
Partially complete transactions were left hanging.
-
WAL log holds the full history of changes.
The recovery process needs to:
-
Analyze the WAL log to figure out what went down.
-
REDO committed transactions to keep promises.
-
UNDO incomplete transactions to maintain integrity.
A subtle case: an ABORTed transaction in the WAL still gets REDO'd first, then UNDO'd. The algorithm is uniform. Some databases optimize this REDO-then-UNDO away for ABORTs to save I/O on long transactions.
When Machine (or disk or network) Crashes
Just Before Crash

Just After Crash

Post-crash reality:
-
Some changes made it to the database (thanks to buffer flushes).
-
Some committed work is missing (lost in RAM).
-
Some incomplete work is on disk but not committed.
-
WAL log is the key to sorting this out.
The Recovery Process
The recovery algorithm in action:
-
Phase 1 - Analysis: Read WAL to build transaction table.
-
Phase 2 - REDO: Replay all changes to reconstruct state.
-
Phase 3 - UNDO: Roll back unfinished transactions.
+ REDO Phase
Purpose: Ensure all finished work survives
Action: Apply changes from WAL using new_values
Order: Forward through the log (oldest to newest)
− UNDO Phase
Purpose: Remove effects of 'unfinished' transactions
Action: Reverse changes using old_values from WAL
Order: Backward through the log (newest to oldest)
After Recovery Complete
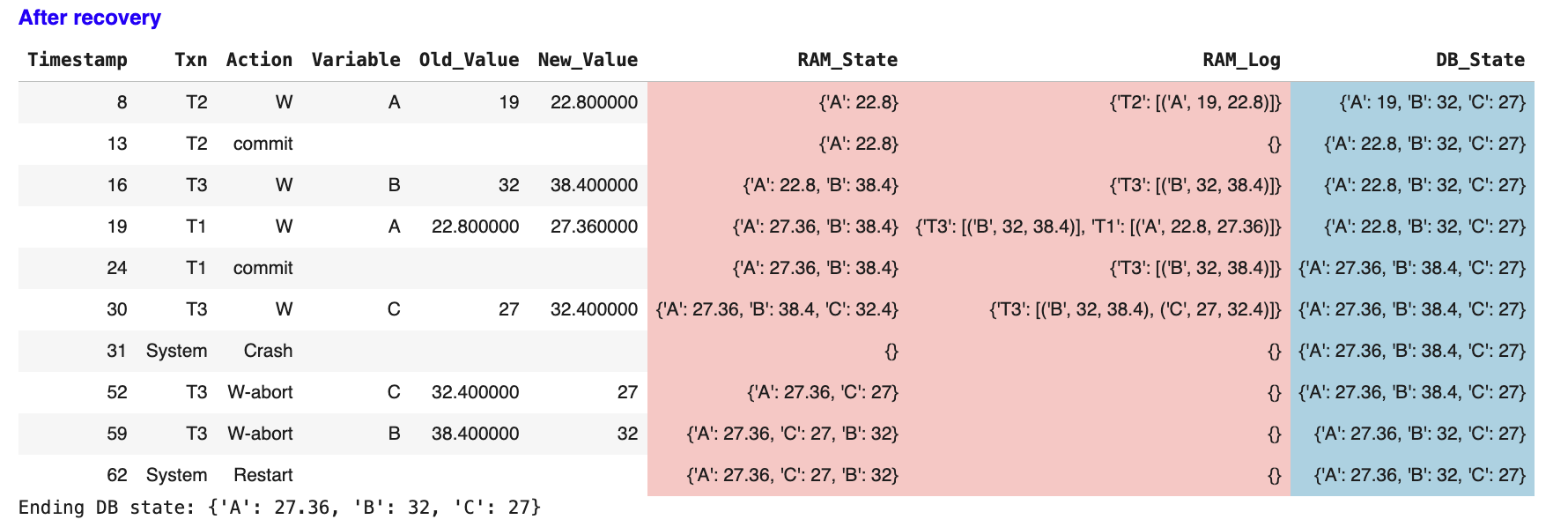
The final state:
-
- All committed transactions are fully applied.
-
− All uncommitted transactions are completely removed.
-
Database is consistent and ready for new transactions.
Why This Works
The WAL is the source of truth!
- It has the complete history of all changes
- It has both old and new values for every change
- It's written durably before any actual data changes
- Even if the database is corrupted, WAL can rebuild everything
Recovery Guarantees
What Recovery Ensures
-
Atomicity: Transactions are all-or-nothing.
-
Durability: Committed work survives crashes.
-
Consistency: Database rules are preserved.
-
Repeatability: Recovery is deterministic.
What Recovery Costs
-
Time: Can take minutes to hours for large databases.
-
I/O: Must read entire WAL since last checkpoint.
-
Availability: Database offline during recovery.
-
Complexity: Requires careful implementation.
Optimizations
Checkpointing
Idea: Periodically flush all dirty pages to disk
Benefit: Limits how far back recovery must go
Trade-off: Checkpoint overhead vs recovery speed
Practice Questions
Test Your Understanding
Q1: Why do we REDO before UNDO?
Q2: What if the system crashes during recovery?
Q3: How do we know which transactions were active at crash time?